
Tags:
When you accept user-generated content on your website, you will, at one point of another, see content that you really wish you hadn't. This could be Joe Bloggs cursing at your article, or John Smith throwing out every insult imaginable in an attempt to goad you or your websites visitors. Usually in these situations you have a couple of options, full moderation or content filtering. It's the latter option I'm focusing on here.
No doubt you've seen clbuttic content filtering before, in-fact the web is full of stories of filtering failures. Filtering is hard. What I wanted to do was write a content filter that wouldn't be too strict but that would effectively block the content that would make sense to block.
The profanity filtering class I wrote is on my GitHub account (I didn't want to host it verbatim here, as search engines and other content filters might end up blocking my website!)
The class has three private member variables, used internally to build the filter matching rules:
$joining_chars- A string of characters which could be used as L-E-T-T-E-R separators
$profanity- An array of basic words to filter out. Each word needs only the basic representation of itself, the class will use basic English rules to guess at pluralisations.
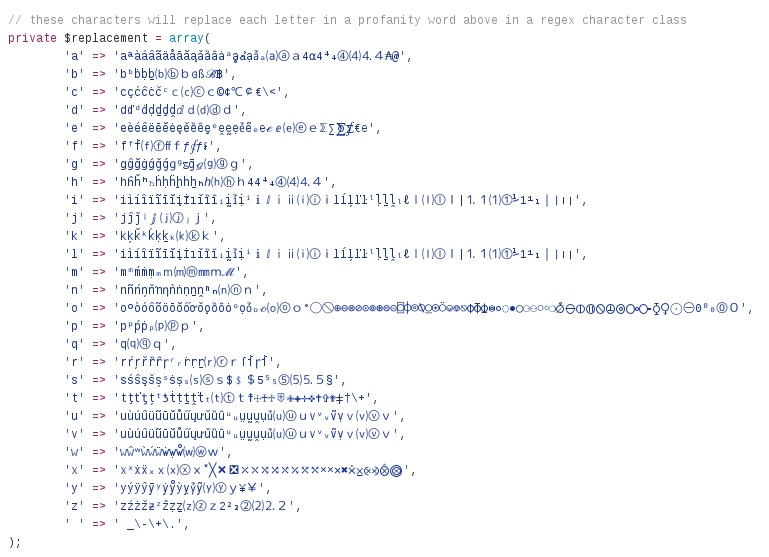
$replactement- An associative array of replacement characters for each letter of the English alphabet, to handle people using letter-like characters in order to bypass a filter
The filter method of the class looks like this:
/**
* return a filtered string
* @param string $filter_line the string to be filtered
* @param string $replace_char optional character to use as the replacement - defaults to *
* @return string
*/
public function filter_string($filter_line, $replace_char='*')
{
/*
* loop through the words in the $profanity array, and for each character swap in the replacement characters
* within the regex character match brackets
* the regex also matches against word boundaries, so clbuttic mistakes don't occur
*/
foreach($this->profanity as $word)
{
$regex = '/(\b|[ \t])';
$regex_parts = array();
// it's ok to use strlen & substr here as the input string should only ever be ascii, never multibyte
for($i=0; $i<strlen($word); $i++)
{
$letter = substr($word, $i, 1);
$regex_parts[] = "[{$this->replacement[$letter]}]+";
}
$regex_parts[] = "[{$this->replacement['e']}]*[{$this->replacement['s']}{$this->replacement['d']}]*";
$regex .= join("[{$this->joining_chars}]*", $regex_parts);
$regex .= '(\b|[ \t])/ui';
$replacement = (mb_strlen($replace_char))?' '.str_pad('', strlen($word), $replace_char).' ':'';
$filter_line = preg_replace($regex, $replacement, $filter_line );
}
return $filter_line;
}
Basically, the filter_string() method loops through all the words defined in the $profanity member variable and builds up a regular expression by swapping out each letter in the profanity word with the string of replacement characters defined in the $replace_char array, with optional "spacer" character string patterns between each letter. Finally the word is capped with a match for either a word boundary or a space (or tab) to ensure it's not going to replace anything within a word (i.e. cl***ic).
The runtime of this is pretty slow, which is understandable considering what it actually has to do, so it's not particularly suited for large texts. I wrote it initially to deal with tweets, and then stored the original and filtered in a database to ensure I wasn't running this for each and every presentation of a tweet.
One last thing to note, because of the heavy use of extended characters, you should try to ensure you have fonts on your system capable of displaying them. This is a representation of what you should be seeing (note the link is just to the image in a new window/tab in-case you're viewing this on a smaller screen):
Comments